用户手册

# 前言
本文档为金蝶Apusic全文检索软件v1.0.2标准版的使用说明,为用户介绍金蝶Apusic全文检索产品,帮助用户快速上手。
# 面向对象
本用户手册主要面向对象为适用金蝶Apusic全文检索的开发人员,以及相关的管理人员和运维人员。
# 版本更新说明
本文根据实际情况进行更新,最新版本包含历史修改记录。
| 日期 | 手册版本 | 适用产品 | 更新说明 |
|---|---|---|---|
| 2024年12月 | V1.0.2 | ASE V1.0.2 | 修改授权认证使用文档 |
# 产品概述
金蝶Apusic全文检索软件(Apusic Search Engine,简称“ASE”)是一个分布式、高扩展、高实时的搜索与数据分析引擎。ASE能够快速地搜索和分析大量的数据,支持全文搜索、聚合、过滤等多种查询方式,能够满足各种不同的搜索和分析需求。
# 概念
在此描述一些概念,该概念是该产品独有的,或者产品依赖的组件所独有的并需要向用户进行解释介绍的
| 概念 | 含义 |
|---|---|
| 索引 | 索引是ASE中的核心概念,类似于传统数据库中的数据表。它是一个拥有相同结构(映射或Schema)的文档集合,用于存储和检索特定类型的数据 |
| 文档 | 文档是ASE中存储的基本单元,相当于关系型数据库中的行。每个文档是一个JSON对象,包含一组键值对(字段),代表一个具体的实体或记录。文档属于某个特定的索引 |
| 映射 | 映射是索引的配置文件,它定义了索引中包含的字段、字段的类型和字段的索引设置。映射定义了索引中文档的格式和结构,以及如何对文档进行索引和搜索 |
| 索引词 | 索引词是索引中用于搜索和索引的词语,可以是单个单词、短语、数字、日期等。索引词可以是任意的文本,也可以是数字、日期等特殊类型的值 |
| 文本 | 文本是索引中用于搜索和索引的文本内容,可以是任意的文本,也可以是数字、日期等特殊类型的值 |
| 分析器 | 分析器是ASE中用于对文本进行分词和过滤的组件,它根据指定的规则将文本分割成独立的单词,并去除停用词和标点符号等,从而实现文本的预处理和索引 |
# 功能清单
| 功能类别 | 功能项 | 功能描述 |
|---|---|---|
| 一、搜索与全文检索 | 全文搜索 | 支持基于倒排索引的全文检索,包括模糊匹配、前缀查询、通配符查询等 |
| 分词器与分析器 | 内置多种分词器(Standard、Whitespace、Keyword等),支持自定义分词器 | |
| 高亮显示 | 支持搜索关键词高亮返回 | |
| 模糊搜索 / 近似搜索 | 支持 fuzzy 查询、近似匹配(如编辑距离) | |
| 多字段搜索 | 支持 multi-match、multi-field 查询 | |
| 搜索模板 | 支持预定义查询模板,动态传参 | |
| 多语言支持 | 支持多语言分词与分析(内置中文IK分词器) | |
| 二、结构化搜索与聚合分析 | 聚合(Aggregations) | 支持指标聚合(avg, sum, min, max)、桶聚合(terms, date_histogram)、管道聚合等 |
| 嵌套聚合 | 支持多层嵌套的聚合分析 | |
| 矩阵聚合 / 管道聚合 | 支持 stats、percentiles、derivative 等高级聚合 | |
| 时间序列聚合 | 支持基于时间的聚合(如 date_histogram) | |
| Composite Aggregation | 支持复合聚合,用于深度分页或导出 | |
| 三、排序与相关性控制 | 相关性评分(BM25) | 支持默认的 BM25 相关性算法,可自定义评分脚本 |
| 自定义评分(Function Score) | 支持脚本评分、函数组合影响排序 | |
| 排序(Sorting) | 支持多字段排序,包括脚本排序 | |
| 四、数据摄取与写入 | RESTful API 写入 | 支持通过 HTTP JSON API 写入文档 |
| 批量写入(Bulk API) | 支持批量导入,提高写入效率 | |
| Index API / Update API / Delete API | 支持单文档增删改查 | |
| Ingest Pipeline | 支持数据写入前的预处理(如 grok、rename、convert 等) | |
| 数据格式支持 | 支持 JSON、CSV(通过工具)、NDJSON 等 | |
| 五、数据查询与访问 | 分页查询 | 支持 from/size 分页,以及更高效的 search_after |
| Scroll 查询 | 支持高效遍历大量数据(快照方式) | |
| Point in Time (PIT) | 支持基于时间点的快照查询,配合 search_after 实现稳定分页 | |
| 多索引查询 | 支持同时查询多个索引(如 log-2024.01*, logs-*) | |
| 字段过滤 / Source 过滤 | 支持只返回指定字段,减少网络开销 | |
| 六、数据管理 | 索引管理(CRUD) | 支持创建、删除、查看索引,配置 mappings & settings |
| 索引模板(Index Templates) | 支持预定义索引的 mappings 和 settings 模板 | |
| 别名(Aliases) | 支持为索引设置别名,实现零停机切换、路由等 | |
| 数据生命周期管理(ILM) | 支持索引的自动滚动、冻结、删除策略 | |
| 冷热数据分层(Hot-Warm-Cold) | 支持通过节点属性与 ILM 实现数据分层存储 | |
| Reindex API | 支持跨索引或跨集群的数据迁移与重建 | |
| 七、分布式与高可用 | 分布式架构 | 支持数据分片(Shards)与副本(Replicas),自动分布与负载均衡 |
| 集群自动发现 | 节点自动发现与集群组建 | |
| 故障检测与自动恢复 | 节点宕机后自动重新分配分片,主分片故障时副本提升 | |
| 分片再平衡 | 集群自动重新平衡分片分布 | |
| 多可用区部署支持 | 支持跨机房 / 区域部署,保障容灾 | |
| 八、安全与权限控制 | 用户认证与鉴权 | 支持基本认证、LDAP |
| 角色与权限管理 | 支持细粒度索引/文档/字段级别的访问控制 | |
| TLS / SSL 加密 | 支持节点间通信与客户端通信加密 | |
| 审计日志 | 记录用户操作行为,满足合规要求 | |
| IP 过滤 / 网络层访问控制 | 支持限制访问来源 IP | |
| 九、监控、运维与诊断 | 集群健康检查 | 提供 green / yellow / red 状态,实时监控集群健康 |
| 节点与分片状态 | 支持查看节点、分片、索引的运行状态 | |
| 慢查询日志 | 支持记录慢查询,便于性能优化 | |
| Metrics 监控 | 提供丰富的集群、节点、JVM、搜索等指标 | |
| 日志收集与分析 | ASE自身可用于收集和分析自身或其他系统的日志 | |
| 十、扩展与生态 | 可插拔架构 | 支持通过插件扩展功能) |
| 与 Kibana 类似的可视化工具 | ASE管控台提供图表、仪表盘、日志查看等 | |
| 与 Logstash / Beats 集成 | 可与 ELK 生态工具无缝协作(Logstash、Filebeat 等) |
# 产品安装
# 安装包说明
ASE产品安装包名称结构是:
ASE-版本号-构建日期-CPU架构.tar.gz,
目前仅支持linux平台下arm64和amd64架构:
- linux x86CPU的安装包:
ASE-V1.0.2-20241227-x86_64.tar.gz - linux armCPU的安装包:
ASE-V1.0.2-20241227-aarch64.tar.gz
注:构建日期为ASE产品包具体构建日期,同一个版本可能存在多个构建日期,获取安装包以最新日期为准。
ASE管控台安装包名称结构是:
ASE-dashboard-版本号-CPU架构.tar.gz,
目前仅支持linux平台下arm64和amd64架构:
- linux-x86_64:
ASE-dashboard-V1.0.2-linux-x64.tar.gz: - linux-arm:
ASE-dashboard-V1.0.2-linux-arm64.tar.gz:
# 端口说明
HTTP API 端口 (默认为 9200): 9200端口主要用于对外提供RESTful API接口,允许客户端通过HTTP/HTTPS协议与其进行交互,执行索引文档、搜索查询、集群状态监控等各种操作。例如,当你通过Kibana、curl命令行工具或是其他应用编程方式与ASE进行通信时,通常会通过这个端口。
Transport 端口 (默认为 9300): 9300端口用于ASE集群内部节点间的通信。当集群中的节点需要彼此之间进行数据同步、分片分配、集群健康状况检测以及其它集群管理任务时,它们会通过TCP协议在这个端口上进行通信。此端口不对外开放,通常只在集群内网环境中使用。
# 安装部署模式
ASE支持单节点部署、集群部署。
# 单节点部署
# 获取目标机器环境的对应的安装包
- ASE-V1.0.2-20241227-x86_64.tar.gz
# 在目标机器上,解压ase安装包
tar -xzvf ASE-V1.0.2-20241227-x86_64.tar.gz
# 修改ase的JVM配置和操作系统的资源配置(可跳过)
# JVM配置
ase的jvm配置文件为:config/jvm.options
重要配置项有:
- -Xms1G --> -Xms : JVM堆内存最小大小,如 -Xms2g(单个节点最大堆内存不要超过32G)
- -Xmx1G --> -Xmx : JVM堆内存最大小,如-Xmx2g(单个节点最大堆内存不要超过32G)
- -XX:+UseG1GC --> 使用G1垃圾回收器
- -Djava.io.tmpdir --> JVM临时文件目录
- -XX:+HeapDumpOnOutOfMemoryError --> 当分配内存空间失败时生成dump文件
- -XX:HeapDumpPath --> dump文件存储位置
- -XX:ErrorFile --> 存储JVM严重错误文件地址
这和java应用项目的jvm配置类似,配置的堆内存最好不要超宿主机内存的1/2,因宿主机操作系统也需要相应的运行内存,建议最大堆内存不要超过32G,一般建议最大为31G。
# 操作系统资源限制:ulimit
临时修改:
ulimit -n 65535 -u 4096永久修改:修改
/etc/security/limits.conf# 添加下面内容 soft nofile 65536 hard nofile 655361
2
3
# 操作系统资源限制vm.max_map_count
cat /proc/sys/vm/max_map_count来查看当前的vm.max_map_count值- 修改vm.max_map_count不低于262144
- 使用vim编辑/etc/sysctl.conf
- 在文件末尾添加:
vm.max_map_count=262144 - 保存并重新加载:
sudo sysctl -p
# 其他设置
ASE有许多系统属性,如下表所列,您可以在命令行参数表示法中指定config/jvm.options。
| 属性 | 说明 |
|---|---|
| -Dopensearch.xcontent.string.length.max= | ASE默认不限制 JSON/YAML/CBOR/Smile 字符串字段的最大长度。为了保护您的集群免受潜在的分布式拒绝服务 (DDoS) 或内存问题的影响,您可以将系统opensearch.xcontent.string.length.max属性设置为合理的限制(最大值为 2,147,483,647),例如-Dopensearch.xcontent.string.length.max=5000000 |
| -Dopensearch.xcontent.fast_double_writer=[true|false] | 默认情况下,ASE 使用 Java 运行时环境提供的默认实现来序列化浮点数。将此值设置为true使用 Schubfach 算法,该算法速度更快,但可能会导致精度略有差异。默认为false |
| -Dopensearch.xcontent.depth.max= | 默认情况下,ASE不对 JSON/YAML/CBOR/Smile 文档的最大嵌套深度施加任何限制。为了保护您的集群免受潜在的 DDoS 或内存问题,您可以将opensearch.xcontent.depth.max系统属性设置为合理的限制(最大值为 2,147,483,647),例如-Dopensearch.xcontent.name.length.max=1000。 |
| -Dopensearch.xcontent.codepoint.max= | 52428800默认情况下,ASE对 YAML文档的最大大小(以代码点为单位)施加限制。为了保护您的集群免受潜在的 DDoS 或内存问题,您可以将opensearch.xcontent.codepoint.max系统属性更改为合理的限制(最大值为 2,147,483,647)。例如,-Dopensearc.xcontent.codepoint.max=5000000。 |
# 配置KBC授权
- 把申请的kbc授权等文件,修改为license.lic,放置在ase安装目录(更多授权配置相关可以查看:License验证和使用)
# 启动ASE
启动ase:
./bin/ase待ASE启动完成后,出现下面图,则启动完成
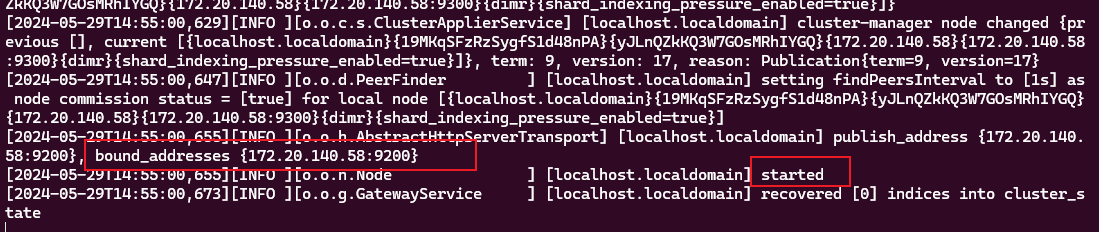
访问获取节点信息: http://127.0.0.1:9200
使用curl获取节点信息
curl http://127.0.0.1:9200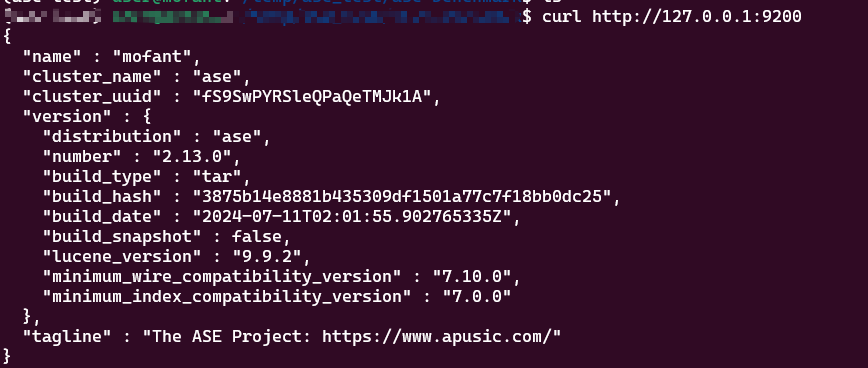
# Docker部署
ASE提供arm和x86的Docker系统镜像包,可通过Docker安装部署ASE.
# 安装包说明
- ASE压缩安装包名称
- linux docker arm镜像包:
ASE-V1.0.2-Docker-202503-aarch64-kylin.tar.gz - linux docker x86_64镜像包:
ASE-V1.0.2-Docker-202503-x86_64-kylin.tar.gz
注: 安装包日期可能不同,请根据实际情况选择。
# 安装步骤
- 导入镜像
docker load < ASE-V1.0.2-Docker-202503-x86_64-kylin.tar.gz
- 创建容器依赖文件
- license.xml:ASE授权文件,可参考:License验证和使用
- ase.yml:ASE配置文件,如果没有可以参考以下两行内容
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["0.0.0.0"]
2
3
- 运行镜像
docker run \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-v /path/to/license.xml:/opt/ase/license.xml \
-v /path/to/ase.yml:/opt/ase/config/ase.yml \
harbor.apusic.com/apusic/ase:V1.0.2-202503-x86_64-kylin
2
3
4
5
6
注:
- =-e 挂载license.xml到容器/opt/ase
- -e 挂载ase.yml到容器/opt/ase/config/ase.yml
- 启动镜像名称请根据实际填写
- 如果提示错误
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144],则查看单机部署的操作系统资源限制内容调整。
- 测试服务 使用curl http://127.0.0.1:9200请求服务获取服务信息, 如下为正常启动
curl http://127.0.0.1:9200
{
"name" : "868b947c6f23",
"ase_version" : "1.0.2",
"cluster_name" : "ase",
"cluster_uuid" : "_na_",
"version" : {
"distribution" : "ase",
"number" : "7.17.26",
"build_type" : "tar",
"build_hash" : "2b3edfac59f74aab011cb8a7e94a7860a77e14ea",
"build_date" : "2025-03-14T09:09:47.334380683Z",
"build_snapshot" : false,
"lucene_version" : "9.9.2",
"minimum_wire_compatibility_version" : "7.17.26",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The ASE Project: https://www.apusic.com/"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 集群安装
ASE集群部署主要用于构建高可用、高并发、可水平扩展的数据检索和分析平台。它通过在多台物理或虚拟服务器上安装并配置ASE节点,这些节点通过共享相同的集群名称相互识别并组成集群。每个节点都能存储数据分片和备份分片,实现数据冗余和负载均衡。集群内部通过选举机制自动管理主副节点关系,保证数据一致性。
# ASE部署节点可以划分为以下角色
- 主节点: 主节点是管理集群状态的(对所有资源要求都不高)
- 协调节点:协调节点是接受客户端请求并分发到相应数据节点的,并合并搜索结果(对网络资源要求高,对CPU和内存也有一定的要求)
- 数据节点:数据节点是读写数据的(对内存、CPU和IO要求高)
注:一般来说,在生产环境中,为了节省资源一个节点一般都是有多个角色,很少将节点作为单一角色来使用。
- 最小的集群:将一个节点当作所有角色来使用(每个节点既是数据节点,也是主节点和协调节点),如上面的单节点部署模式。
- 初等规模:分成主节点和其他节点(数据节点也是协调节点);分成协调节点和其他节点(数据节点也是主节点);
- 中高等规模:将数据节点、主节点和协调节点分开。
下面是创建ASE集群样例的过程和步骤:
# 集群列表和节点角色划分(参考)
| 节点名称 | 节点IP | 节点角色 | 其他说明 |
|---|---|---|---|
| node-200 | 192.168.0.200 | 数据节点 1 + 主节点1 | |
| node-201 | 192.168.0.201 | 数据节点 2 + 主节点2 | |
| node-202 | 192.168.0.202 | 数据节点 3 + 主节点3 | |
| node-203 | 192.168.0.203 | 协调节点1 | |
| node-204 | 192.168.0.204 | 协调节点2 | |
| node-205 | 192.168.0.205 | 协调节点3 |
# 在6个节点中,上传同一份安装包,并解压到安装目录
tar -zxvf ASE-V1.0.2-20241227-x86_64.tar.gz
# 修改每个节点的config/ase.yml文件,添加以下内容
# 集群名称
cluster.name: ase-search
# 按照上面的节点列表,改成每个节点的名称
node.name: node-200
# 修改数据存放路径和日志路径
path.data: /home/ase-user/data
path.logs: /home/ase-user/log
# 按照上表,改成每个的IP或主机名
network.host: 192.168.0.200
http.port: 9200
discovery.seed_hosts: ["192.168.0.200:9300", "192.168.0.201:9300","192.168.0.202:9300","192.168.0.203:9300","192.168.0.204:9300","192.168.0.205:9300"]
# 这里填写主节点名称
cluster.initial_master_nodes: ["node-200", "node-201","node-202"]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
注:
node.name:每个节点要改成对应节点的名称network.host:每个节点要改成对应节点的主机名或IPdiscovery.seed_hosts:集群中的节点列表cluster.initial_master_nodes:集群初始化时主节点列表,必须是节点名称而非IP端口
# 在主节点上加入以下配置
在三个主节点[node-200, node-201, node-202]三个节点的ase.yml配置文件中,添加
node.roles: [cluster_manager]
注:如果node.roles原来有其他角色,要合并到一起,如原来是data节点,那么就设置为[data,cluster_manager]
# 在所有协调节点上配置
在三个协调节点[node-203,node-204,node-205]三个节点的ase.yml配置文件中,添加
node.roles:[]
注:没有任何指定角色的节点就是协调节点(默认所有的节点都是协调节点)
# 在所有数据节点上加入以下配置
在三个主节点[node-200, node-201, node-202]三个节点的ase.yml配置文件中,修改以下配置:
node.roles: [data]
注:如果node.roles原来有其他角色,要合并到一起,如原来是cluster_manager节点,那么就设置为[cluster_manager,data]
# 启动各节点
依次启动各节点,如果节点启动失败,可根据错误来进行处理
通过ip:9200的形式在浏览器中访问,查看各节点是否启动成功
如 http://192.168.0.200:9200,如果可以成功访问说明启动成功
# 检测集群是否搭建成功
在浏览器中http://192.168.0.200:9200/_cat/nodes
查看结果是否如下:
192.168.0.201 33 96 1 0.19 0.18 0.19 dim - node-201
192.168.0.200 22 94 0 0.13 0.22 0.18 dim * node-200
192.168.0.202 16 81 1 0.18 0.32 0.20 dim - node-202
192.168.0.205 17 96 1 0.40 0.32 0.19 - - node-205
192.168.0.203 15 78 1 0.27 0.34 0.22 - - node-203
192.168.0.204 15 95 0 0.48 0.45 0.25 - - node-204
2
3
4
5
6
注:
- role那一行中,是多个角色的组合
- d: 数据节点(data)
- i: 预处理节点(ingest)
- m: 主节点备选节点(master)
- master那一行,表示当前节点是否为主节点
*: 是主节点-: 不是主节点
# 管控台安装
已经部署好ASE情况下安装ASE管控台的步骤如下:
- 在知识中心下载对应的ASE-dashboard安装包。
- 上传到ase安装服务器,并解压。
- 配置连接ase的地址和端口。
- 启动服务。
注:ase需要开启ssl和创建用户【参考用户手册的:SSL和设置admin用户密码】
# ASE管控台下载和安装
下载ASE管控台安装包后,上传到目标服务器/opt目录,解压(示例为arm版本):
tar -zxvf ASE-dashboard-V1.0.2-linux-arm64.tar.gz
# 配置连接ase的地址和端口
进入安装目录:cd /opt/ASE-dashboard-V1.0.2-linux-arm64/
修改配置文件config/opensearch_dashboards.yml,修改opensearch.hosts内容:
opensearch.hosts: [https://127.0.0.1:9200] opensearch.ssl.verificationMode: none1
2配置监听当前局域网,修改配置文件
config/opensearch_dashboards.yml,修改15行的server.host内容为当前机器IP:server.host: "当前机器IP"1启动服务
./bin/ase-dashboard --allow-root &1
# 访问控制台
浏览器访问:http://ip地址:5601 输入ase的用户名和密码,即可进入ASE管控台。

# 快速开始
# 使用管控台
在部署好ASE和管控台后(部署参考用户手册或安装手册),可以通过管控台的Dev tools工具来使用REST API。
- 登录管控台,点击左侧导航栏的Dev tools,进入Dev tools页面。
# 文档增删改查语法
可以通过PUT、DELETE、POST、GET语法实现对于文档的增删改查方法。
PUT
- 创建资源:如果指定资源的id不存在,PUT请求可能会被用来创建该资源。
- 更新资源:如果向一个已存在的资源id发送请求,该资源的当前状态会被请求体中的新状态替换。
DELETE
- 删除资源:如果指定资源的id存在,DELETE请求可能会被用来删除该资源。
- 删除资源列表:如果指定资源的id不存在,DELETE请求可能会被用来删除该资源的元数据。
GET
- 获取资源:如果指定资源的id存在,GET请求可能会被用来获取该资源的元数据。
- 获取资源列表:如果指定资源的id不存在,GET请求可能会被用来获取该资源的元数据。
POST
- 创建资源:使用POST请求时,你通常向资源的集合URL发送请求,而不是向特定资源的URL发送请求。服务器会处理请求体中的数据,并创建一个新的资源实例,然后返回新创建资源的元数据(如ID和位置)。
- 执行操作:在某些情况下,POST请求也被用于执行不直接对应于资源创建的操作,比如提交表单数据或触发某些处理流程。
# PUT 创建文档
- PUT创建文档基本格式
PUT <index>/_doc/<id>
{ "JSON":"document" }
2
PUT:请求通常用于更新或创建资源,在大多数RESTful API中,PUT请求主要用于更新已存在的资源。在使用PUT请求的时候,需要指定资源的完整URL(包括ID)。
## 例子
PUT /account/_doc/3
{
"name": "Apusic",
"type": "test"
}
2
3
4
5
6
## 结果
{
"_index": "account", ##显示索引名
"_id": "3",
"_version": 1,
"result": "created", ##操作类型
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 2
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# POST创建文档基本格式
POST <index>/_doc
{ "JSON":"document" }
POST <index>/_doc/<id>
{ "JSON":"document" }
2
3
4
5
POST:请求通常用于创建新的资源,不需要指定资源的id,而是在创建资源的时候自动生成相应id,当然也可以在自行设置资源id。
## 例子
POST movies/_doc
{ "title": "Spirited Away" }
2
3
## 结果
{
"_index": "movies",
"_id": "1pFhApEBaB3Z-jDLo_us",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# DELETE删除文档
DELETE:通过方法可以执行一系列相关删除数据操作,常见的方法如下:
删除单个文档
## 删除单个文档 DELETE <index>/_doc/<id> ## curl命令 (索引为my_index,id为123) curl -X DELETE "localhost:9200/my_index/_doc/123" -H 'Content-Type: application/json'1
2
3
4执行操作,需要指定对应的索引以及id,在使用curl命令时,localhost:9200默认地址,需要根据实际opensearch的集群地址。
## 例子 DELETE movies/_doc/1pFhApEBaB3Z-jDLo_us1
2## 结果 { "_index": "movies", "_id": "1pFhApEBaB3Z-jDLo_us", "_version": 2, "result": "deleted", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 3 }1
2
3
4
5
6
7
8
9
10
11
12
13
14删除多个文档
通过POST方法采用_delete_by_query API来根据查询条件删除多个文档。
POST /<index>/_delete_by_query { "query": { "match": { "field_name": "field_value" } } }1
2
3
4
5
6
7请求会删除索引中所有file_name字段值为field_value的文档。
## 例子 { "took": 19, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 3, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "account", "_id": "3", "_score": 1, "_source": { "name": "Apusic", "type": "test1" } }, { "_index": "account", "_id": "1", "_score": 1, "_source": { "name": "Apusic", "type": "test" } }, { "_index": "account", "_id": "2", "_score": 1, "_source": { "name": "Apusic", "type": "test" } } ] } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47对上述文档集合进行多文档删除处理
POST /account/_delete_by_query { "query":{ "match":{ "type":"test" ##删除其中type=test的文档 } } }1
2
3
4
5
6
7
8# 结果 { "took": 867, "timed_out": false, "total": 2, "deleted": 2, "batches": 1, "version_conflicts": 0, "noops": 0, "retries": { "bulk": 0, "search": 0 }, "throttled_millis": 0, "requests_per_second": -1, "throttled_until_millis": 0, "failures": [] }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# PUT更新文档
PUT更新文档基本格式
PUT请求在向一个已经创建的文档资源id发送请求,该资源的当前状态会被请求体的新状态进行修改。
PUT <index>/_doc/<id> { "JSON":"document" }1
2## 例子 PUT /account/_doc/2 { "name": "Apusic", "type": "updta test" }1
2
3
4
5
6## 结果 { "_index": "account", "_id": "2", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 14, "_primary_term": 4 }1
2
3
4
5
6
7
8
9
10
11
12
13
14POST更新文档基本格式
POST请求通过
_update命令更新已经存在的数据,在内容中包含所要进行更新的数据类型及内容。POST <index>/_update/<id> { "filed_name":"filed_update" , ## 常用的filed_name为doc,更新文档主体内容 ... }1
2
3
4
5## 例子 POST /account/_update/2 { "doc": { "name":"Apusic_update" } }1
2
3
4
5
6
7## 结果 { "_index": "account", "_id": "2", "_version": 3, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 15, "_primary_term": 4 }1
2
3
4
5
6
7
8
9
10
11
12
13
14
# GET获取/查询文档
基本请求格式: _search来获取一个索引下所有的值
GET /<index>/_search ##请求获取索引下所有值 { "query": { "match_all":{} } }1
2
3
4
5
6## 例子 GET /account/_search { "query": { "match_all": {} } }1
2
3
4
5
6
7##结果 { "took": 1, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 2, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "account", "_id": "1", "_score": 1, "_source": { "name": "Apusic", "type": "test" } }, { "_index": "account", "_id": "2", "_score": 1, "_source": { "name": "Apusic", "type": "test" } } ] } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38除上述之外,可以通过
<index>/_doc/<id>读取索引下指定的一个文档。## 例子 GET /account/_doc/1 ##结果 { "_index": "account", "_id": "1", "_version": 1, "_seq_no": 11, "_primary_term": 3, "found": true, "_source": { "name": "Apusic", "type": "test" } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16使用查询字符串参数的GET请求
GET /<index>/_search?q=*:*1这里,q=: 是一个 Lucene 查询字符串,意味着“匹配所有文档”。但是,请注意,由于 GET 请求的 URL 长度限制和敏感信息(如查询体)不应该放在 URL 中,因此这主要用于演示或非常简单的查询。
POST参数查询
在实际应用中,由于 GET 请求的限制(如 URL 长度和不支持请求体),通常会使用 POST 请求来执行复杂的查询或检索大量数据。POST 请求允许你在请求体中发送 JSON 格式的查询和数据。
POST /<index>/_search { "query": { "match": { "field_name": "value_to_match" } } }1
2
3
4
5
6
7
8## 例子 POST /account/_search { "query":{ "match":{ "_id":"1" } } }1
2
3
4
5
6
7
8
9## 结果 { "took": 10, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1, "relation": "eq" }, "max_score": 1, "hits": [ { "_index": "account", "_id": "1", "_score": 1, "_source": { "name": "Apusic", "type": "test" } } ] } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 使用REST API
REST API入口: ASE节点IP地址:9200(默认端口)。 下面是参考,具体的内容可以参考上面的管控台的API文档。
# 创建文档
HTTP方法: PUT或POST
HTTP请求路径: /索引名称/类型名称/文档id
HTTP请求体: json
put文档必须要指定文档 _id
post可指定,也可不指定,不指定则会随机生成一个 _id。
如果没有提前设定索引中字段类型而直接添加文档,ase会对字段数据给自动数据类型,新字段会永久补充进去mapping。
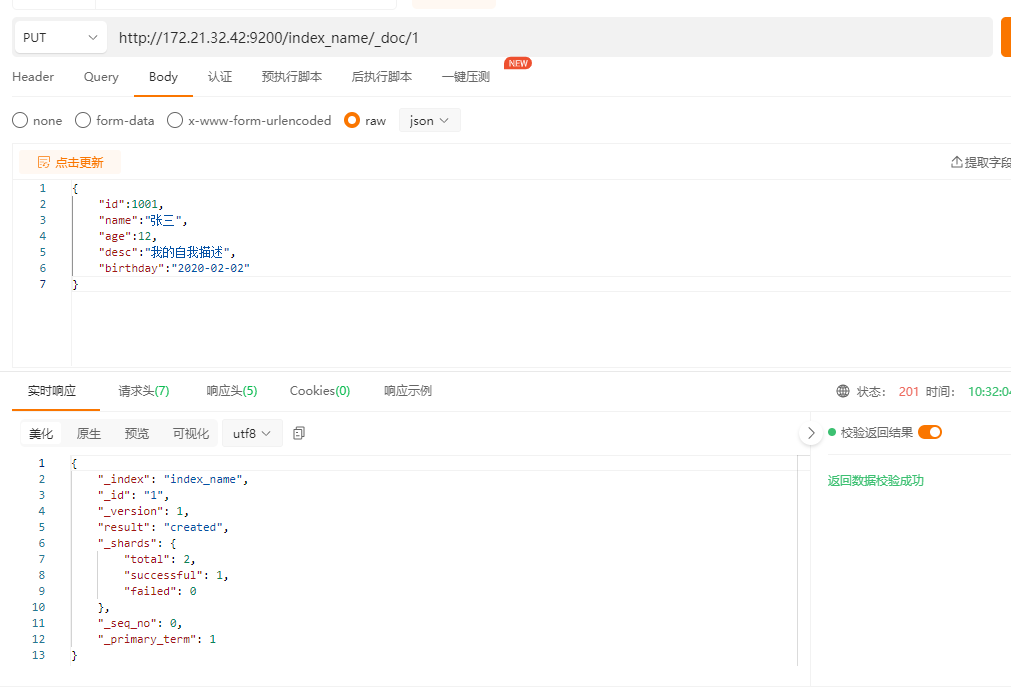
参考样例
- put指定ID(如果已经有对应数据,则修改,无则创建)
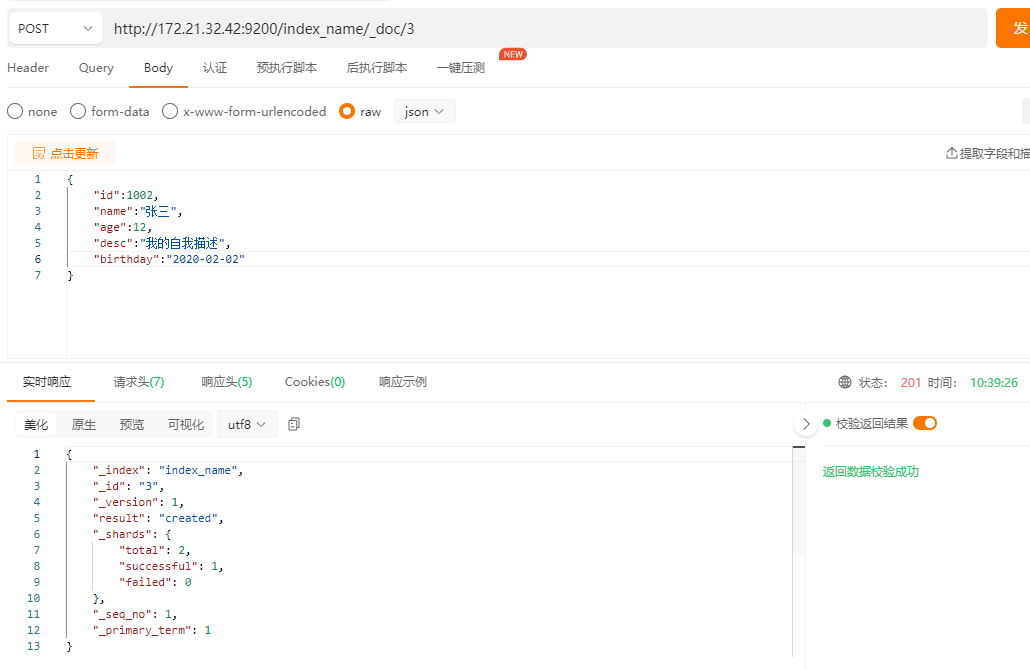
POST指定ID(有则修改,无则创建)
post不指定id,自动生成文档id(每次执行都是创建新的文档)
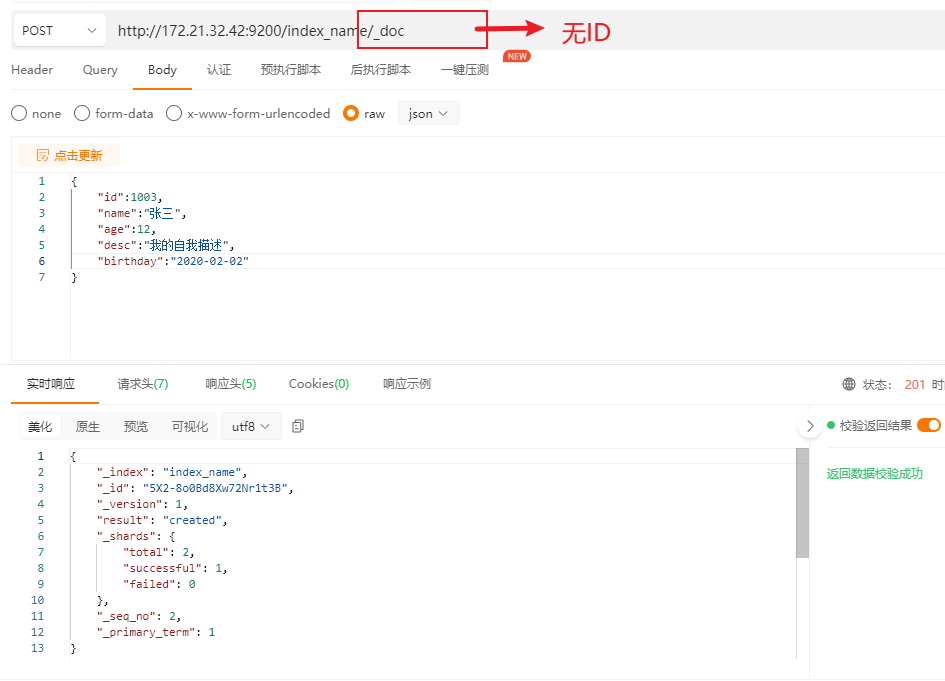
# 查询文档
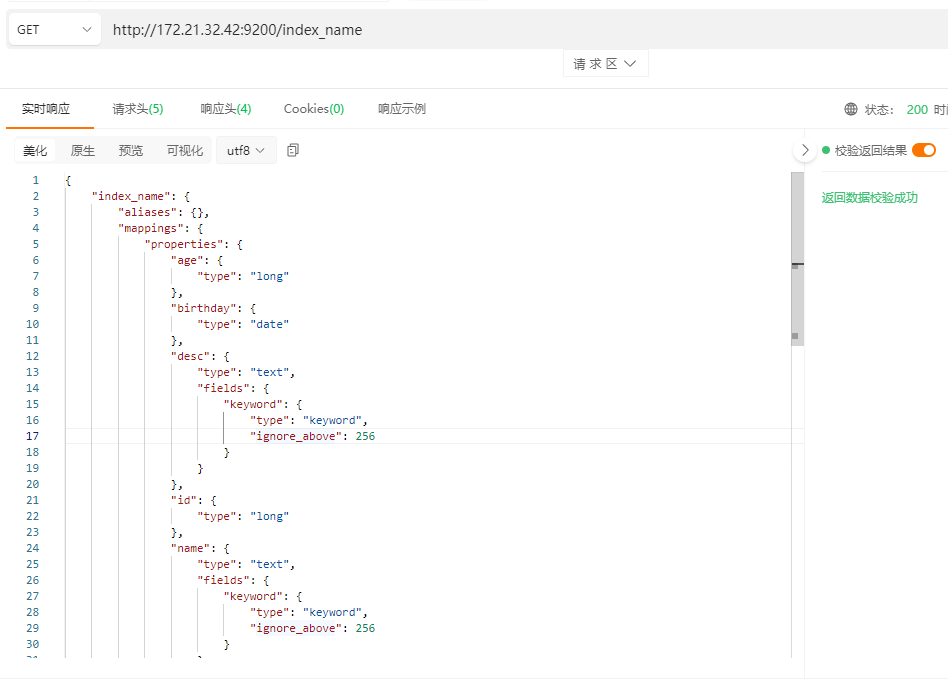
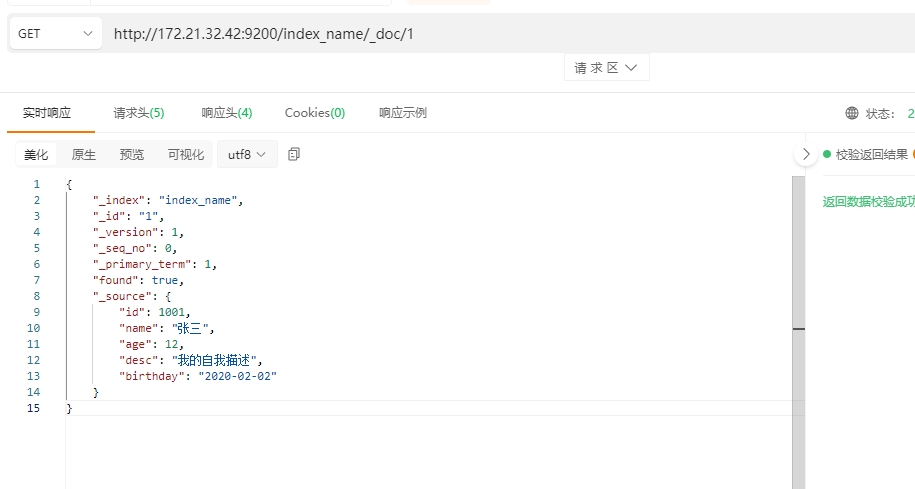
HTTP方法: GET
HTTP请求路径:/索引名称/类型名称/文档id
HTTP请求体: 无
查询上面创建的index_name索引信息
查询文档内容
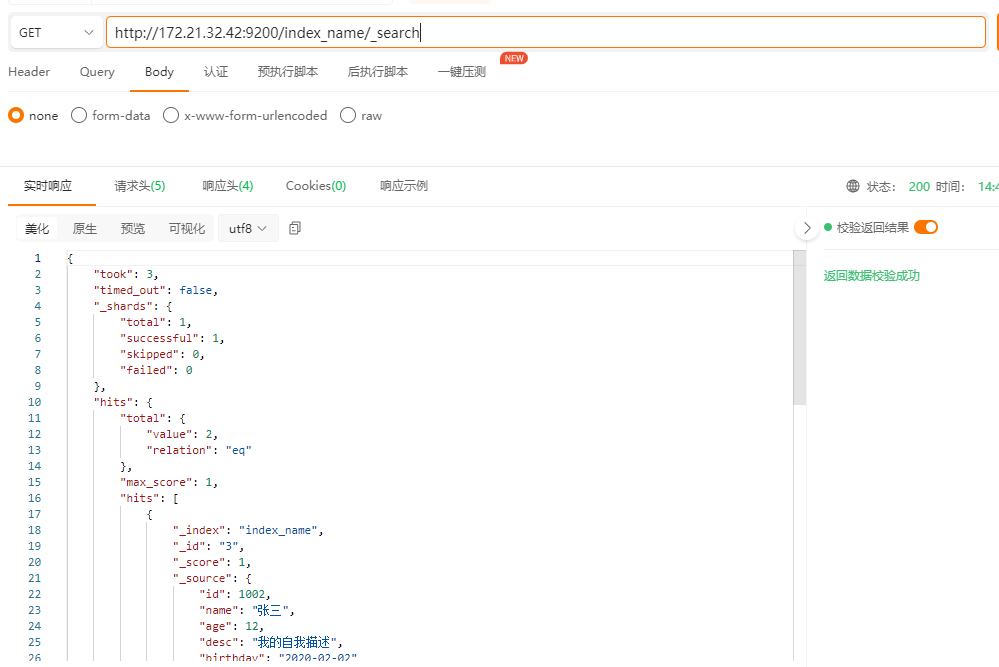
查询全部文档
请求路径: /索引名称/_search
模糊查询
请求路径: /索引名称/_search?q=name:XXX
如下搜索名称包含“三”的记录
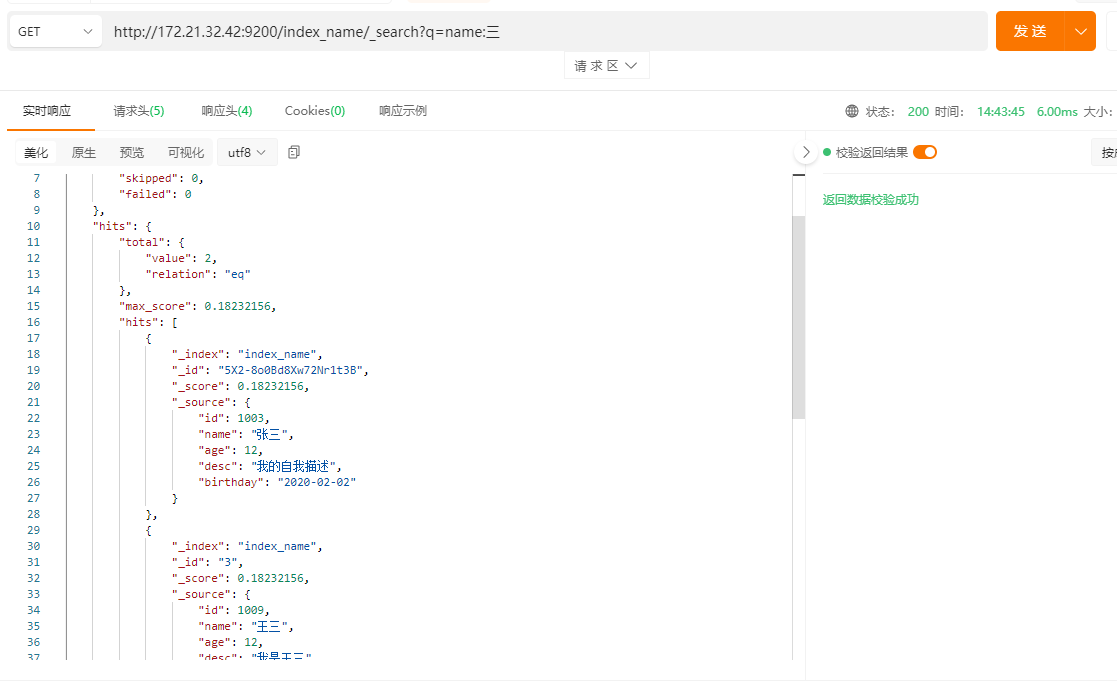
# 删除文档
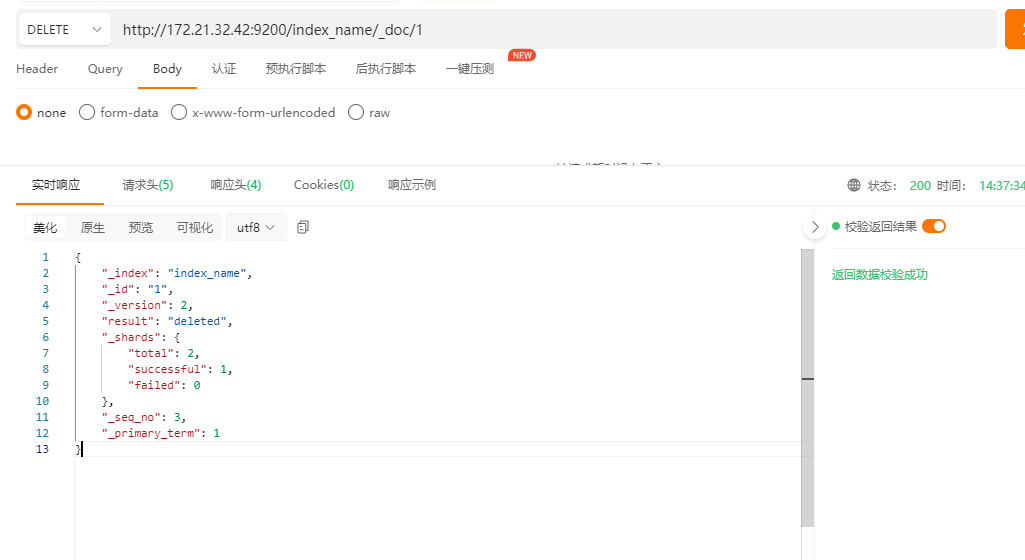
HTTP方法: DELETE
HTTP请求路径: /索引名称/类型名称/文档ID
HTTP请求体: 无
删除index_name中id等于1的记录
# 创建ISM生命周期管理
索引状态管理(ISM)是一款插件,它允许根据索引年龄、索引大小或文档数量的变化触发定期的管理操作,从而实现自动化。使用ISM插件,可以定义策略来自动处理索引更新或删除,以满足特定的用例。
例如,可以定义一个策略,使索引在30天后进入read_only状态,然后在设定的90天后将其删除。此外,还可以设置策略,在索引被删除时发送通知消息。
在一定时间后执行索引滚动更新,或者在非高峰时段对索引运行force_merge操作,可以提高高峰时段的搜索性能。通过应用合理的索引策略,可以实现索引的自动清理、数据热-温-冷自动迁移、自动备份、force merge、rollover、rollup、close、open、delete等功能,以确保数据以尽可能最具成本效益的方式正确存储。
# ISM入门
策略是一组描述如何管理索引的规则。有关创建策略的信息,请参下一个章节策略介绍。 可以使用可视化编辑器或 JSON 编辑器来创建策略。与JSON编辑器相比,可视化编辑器(管控台)通过将流程分为创建错误通知、定义 ISM 模板和添加状态,提供了一种更结构化的策略定义方式。
创建策略后,需要将策略附加到一个或多个索引上,可以在策略中设置,ism_template这样当创建与ISM 模板模式匹配的索引时,插件会自动将策略附加到该索引。
# 使用JSON创建策略
以下示例说明如何创建一个策略,该策略自动附加到名称以index_name-开头的所有索引。
PUT _plugins/_ism/policies/policy_id
{
"policy": {
"description": "Example policy.", # 描述
"default_state": "...",
"states": [...],
"ism_template": {
"index_patterns": ["index_name-*"],
"priority": 100
}
}
}
2
3
4
5
6
7
8
9
10
11
12
# ISM样例
使用ISM创建7天后自动删除的策略,并且这个策略自动绑定到全部以
company开头的索引。PUT /_plugins/_ism/policies/d7d { "policy": { "description": "delete 7 after day", "default_state": "delete", "schema_version": 1, "states": [ { "name": "rollover", "actions": [ { "rollover": { "min_index_age": "7d", "min_doc_count": 1 } } ], "transitions": [ { "state_name": "delete" } ] }, { "name": "delete", "actions": [ { "delete": {} } ] } ], "ism_template": { "index_patterns": ["company*"], "priority": 101 } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38一个作业将触发滚动操作,并创建一个新索引。接下来,将另一个文档添加到这两个索引中。然后,新作业将导致第二个索引指向日志别名,并且旧索引将由于别名操作而被删除。
PUT /_plugins/_ism/policies/rollover_policy?pretty { "policy": { "description": "Example rollover policy.", "default_state": "rollover", "states": [ { "name": "rollover", "actions": [ { "rollover": { "min_doc_count": 1 } } ], "transitions": [{ "state_name": "alias", "conditions": { "min_doc_count": "2" } }] }, { "name": "alias", "actions": [ { "alias": { "actions": [ { "remove": { "alias": "log" } } ] } } ] } ], "ism_template": { "index_patterns": ["log*"], "priority": 100 } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45接下来,创建一个要启用该策略的索引模板
PUT /_index_template/ism_rollover? { "index_patterns": ["log*"], "template": { "settings": { "plugins.index_state_management.rollover_alias": "log" } } }1
2
3
4
5
6
7
8
9接下来,更改集群设置以每分钟触发作业:
PUT /_cluster/settings?pretty=true { "persistent" : { "plugins.index_state_management.job_interval" : 1 } }1
2
3
4
5
6接下来创建一个新索引:
PUT /log-000001 { "aliases": { "log": { "is_write_index": true } } }1
2
3
4
5
6
7
8最后,向索引中添加一个文档来触发作业:
POST /log-000001/_doc { "message": "dummy" }1
2
3
4可以使用 Alias 和 Index API 验证以下步骤:
GET /_cat/aliases?pretty1GET /_cat/indices?pretty1注意:
index和remove_index参数不支持别名。
# ISM策略介绍
策略是定义以下内容的 JSON 文档:
- 索引可以处于的状态,包括新索引的默认状态。例如,可以将状态命名为“热” 、 “温”、“删除”等等
- 当索引进入某种状态时,可以让插件采取的任何操作,例如执行滚动更新。
- 索引进入新状态必须满足的条件,称为转换。例如,如果索引已超过八周,可能希望将其移至“删除”状态。
换句话说,策略定义了索引可以处于的状态、处于某种状态时要执行的操作以及在状态之间转换必须满足的条件。
可以完全灵活地设计策略。可以创建任何状态、转换到任何其他状态,并在每个状态下指定任意数量的操作。
| 关键字 | 描述 | 类型 | 必须 | 只读 |
|---|---|---|---|---|
| policy_id | 策略的名称。 | string | 是 | 是 |
| description | 该政策的人类可读的描述。 | string | 是 | 否 |
| ism_template | 指定 ISM 模板以自动将策略应用到新创建的索引。 | nested list of objects | 否 | 否 |
| ism_template.index_patterns | 指定与新创建的索引名称匹配的模式。 | list of strings | 否 | 否 |
| ism_template.priority | 当多个策略与新创建的索引名称匹配时,指定优先级以消除歧义。 | number | 否 | 否 |
| last_updated_time | 政策上次更新的时间。 | timestamp | 是 | 是 |
| error_notification | 错误通知的目标和消息模板。目标可以是 Amazon Chime、Slack 或 Webhook URL。 | object | 否 | 否 |
| default_state | 每个使用此策略的索引的默认起始状态。 | string | 是 | 否 |
| states | 在策略中定义的状态。 | nested list of objects | 是 | 否 |
# 状态
状态是对托管索引当前所处状态的描述。托管索引一次只能处于一种状态。每个状态都有相关的操作,这些操作在进入状态时按顺序执行,并且转换在所有操作完成后进行检查。
下表列出了可以为某个状态定义的参数。
| 关键字 | 描述 | 类型 | 必需 |
|---|---|---|---|
name | 状态的名称。 | string | 是 |
actions | 进入状态后要执行的操作。 | nested list of objects | 是 |
transitions | 下一个状态以及转换到这些状态所需的条件。如果不存在转换,则策略假定它已完成并现在可以停止管理索引。 | nested list of objects | 是 |
# 操作
操作是策略在进入特定状态时按顺序执行的步骤。 ISM 按照操作定义的顺序执行操作。例如,如果定义操作 [A、B、C、D],ISM 将执行操作 A,然后根据集群设置进入休眠期 plugins.index_state_management.job_interval。休眠期结束后,ISM 继续执行剩余操作。但是,如果 ISM 无法成功执行操作 A,则操作结束,并且不会执行操作 B、C 和 D。
还可以选择定义操作的超时期限,如果超过该期限,则强制操作失败。例如,如果超时设置为 1d,并且 ISM 在一天内未完成操作,则即使重试后,操作也会失败。
| 范围 | 描述 | 类型 | 必需 | 默认 |
|---|---|---|---|---|
timeout | 操作的超时期限。接受分钟、小时和天的时间单位。 | time unit | 否 | - |
retry | 该操作的重试配置。 | object | 否 | 具体到行动 |
该retry操作具有以下参数
| 范围 | 描述 | 类型 | 必需 | 默认 |
|---|---|---|---|---|
count | 重试的次数。 | number | 是 | - |
backoff | 重试时使用的退避策略类型。有效值为 Exponential、Constant 和 Linear。 | string | 否 | 指数 |
delay | 重试之间等待的时间。接受分钟、小时和天的时间单位。 | time unit | 否 | 1分钟 |
以下示例操作的超时期限为 1 小时。该策略使用指数退避策略重试此操作三次,每次重试间隔 10 分钟:
"actions": {
"timeout": "1h",
"retry": {
"count": 3,
"backoff": "exponential",
"delay": "10m"
}
}
2
3
4
5
6
7
8
以下是支持的操作:
- 强制合并(force_merge)
- 只读(read_only)
- 读写(read_write)
- 副本数(replica_count)
- 收缩(shrink)
- 关闭(close)
- 打开(open)
- 删除(delete)
- 滚下(rollover)
- 通知(notification)
- 快照(snapshot)
- 索引优先级(index_priority)
- 分配(allocation)
- 卷起(rollup)
# 强制合并(force_merge)
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
max_num_segments | 要减少碎片的段数。 | number | 是 |
wait_for_completion | 布尔值 | 设置为 时false,请求将立即返回,而不是在操作完成后返回。要监视操作状态,请使用请求返回的任务 ID 的Tasks APItrue 。默认值为。 | |
task_execution_timeout | 时间 | 显式任务执行超时。仅当wait_for_completion设置为时才有用false。默认值为1h。 | 否 |
{
"force_merge": {
"max_num_segments": 1
}
}
2
3
4
5
# 只读(read_only)
将托管索引设置为只读。
{
"read_only": {}
}
2
3
将索引设置设为index.blocks.write托管true索引。注意:此块不会阻止索引刷新。
# 读写(read_write)
将托管索引设置为可写。
{
"read_write": {}
}
2
3
# 副本数(replicas)
设置分配给索引的副本数。
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
number_of_replicas | 定义分配给索引的副本数。 | number | 是 |
{
"replica_count": {
"number_of_replicas": 2
}
}
2
3
4
5
# 收缩(shrink)
允许减少索引中的主分片数量。通过此操作,可以指定:
- 目标索引应包含的主分片的数量。
- 目标索引中主分片的最大分片大小。
- 指定一个百分比来缩小目标索引中的主分片的数量。
"shrink": {
"num_new_shards": 1,
"target_index_name_template": {
"source": "_shrunken"
},
"aliases": [
{
"my-alias": {}
}
],
"switch_aliases": true,
"force_unsafe": false
}
2
3
4
5
6
7
8
9
10
11
12
13
| 范围 | 描述 | 类型 | 例子 | 必需 |
|---|---|---|---|---|
| num_new_shards | 收缩索引中 主分片的 最大数量。 | 整数 | 5 | max_shard_size是, 但是它不能与或 一起使用percentage_of _source_shards。 |
| max_shard_size | 目标索引的 分片的最 大大小 (以字节为单位)。 | 关键词 | 5gb | 是,但是不能与 num_new_shards 或一起使用percentage_of _source_shards。 |
| percentage_of_source_shards | 要缩减的原始 主分片数量的百分比。 此参数表示缩减 主分片数量时要 使用的最小百分比 。必须介于0.0到 1.0之间(不含)。 | 百分比 | 0.5 | 是,但不能 与max_shard_size 或一起使用 num_new_shards |
| target_index_name_template | 缩小索引的 名称。接受 字符串和 Mustache变量and。 | 字符串或 胡子模板 | {"source": "_shrunken"} | 否 |
| aliases | 要添加到新索引的别名。 | 目的 | myalias | 否。它必须是别名对象的数组。 |
| switch_aliases | 如果true,则将别名从源索引 复制到目标索引。 如果与字段中的 别名存在名称 冲突aliases, 则使用字段中 的别名aliases 代替名称。 | 布尔值 | true | 否。默认隐式值 为 false,表示默认情 况下不复制 任何别名。 |
| force_unsafe | 如果是true,即使没有副本 ,也会缩小索引。 | 布尔值 | false | 否 |
如果要添加到操作中,参数必须包含别名对象aliases数组。例如,
"aliases": [
{
"my-alias": {}
},
{
"my-second-alias": {
"is_write_index": false,
"filter": {
"multi_match": {
"query": "QUEEN",
"fields": ["speaker", "text_entry"]
}
},
"index_routing" : "1",
"search_routing" : "1"
}
},
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 关闭(close)
关闭管理索引。
{
"close": {}
}
2
3
已关闭的索引仍保留在磁盘上,但不占用 CPU 或内存,无法读取、写入或搜索已关闭的索引。
如果需要保留数据的时间比主动搜索数据的时间长,并且数据节点上有足够的磁盘空间,则关闭索引是一个不错的选择。如果需要再次搜索数据,重新打开已关闭的索引比从快照恢复索引更简单。
# 打开(open)
打开托管索引。
{
"open": {}
}
2
3
# 删除
删除托管索引。
{
"delete": {}
}
2
3
# 滚下(rollover)
当托管索引满足其中一个滚动条件时,将别名滚动到新索引。
ISM根据设置的间隔(而不是连续)在每次执行策略时检查操作条件。如果在执行检查时值已达到或超过*配置的限制,则将执行滚动。例如,如果配置为 100GiB 的值,ISM 可能会检查 99 GiB 处的索引而不执行滚动。但是,如果在下次检查时索引已超过限制(例如 105GiB),则执行操作。min_size
如果需要跳过翻转操作,可以将索引设置index.plugins.index_state_management.rollover_skip为true。例如,如果收到错误消息“缺少别名或未写入索引…”,则可以将参数设置index.plugins.index_state_management.rollover_skip为true并重试跳过翻转操作。
索引格式必须符合以下模式:^.*-\d+$。例如,(logs-000001)。设置index.plugins.index_state_management.rollover_alias为 rollover 的别名。
| 范围 | 描述 | 类型 | 例子 | 必需 |
|---|---|---|---|---|
min_size | 滚动索引所需的主分片存储空间(不计算副本)的最小大小。例如,如果设置min_size为 100 GiB,并且索引有 5 个主分片和 5 个副本分片,每个分片大小为 20 GiB,则所有主分片的总大小为 100 GiB,因此会发生滚动。请参阅上面的重要说明。 | string | 20gb或者5mb | 否 |
min_primary_shard_size | 滚动索引所需的单个主分片的最小存储大小。例如,如果设置min_primary_shard_size为 30 GiB,并且索引中的一个主分片的大小大于条件,则会发生滚动。请参阅上面的重要说明。 | string | 20gb或者5mb | 否 |
min_doc_count | 滚动索引所需的最少文档数。请参阅上面的重要说明。 | number | 2000000 | 否 |
min_index_age | 滚动索引所需的最短期限。索引期限是从创建到现在的时间。支持的单位为d(天)、h(小时)、m(分钟)、s(秒)、ms(毫秒)和micros(微秒)。请参阅上面的重要说明。 | string | 5d或者7h | 否 |
copy_alias | 控制是否将当前索引中的所有别名复制到新创建的索引。默认为false。 | boolean | true或者false | 否 |
{
"rollover": {
"min_size": "50gb"
}
}
2
3
4
5
{
"rollover": {
"min_primary_shard_size": "30gb"
}
}
2
3
4
5
{
"rollover": {
"min_doc_count": 100000000
}
}
2
3
4
5
{
"rollover": {
"min_index_age": "30d"
}
}
2
3
4
5
# 通知(notification)
发送通知。
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
destination | 目标 URL。 | Slack, Amazon Chime, or webhook URL | 是 |
message_template | 消息文本。 | object | 是 |
目标系统必须返回响应,否则通知操作将引发错误。
示例 1:CHIME 通知
{ "notification": { "destination": { "chime": { "url": "<url>" } }, "message_template": { "source": "the index is {{ctx.index}}" } } }1
2
3
4
5
6
7
8
9
10
11
12示例 2:自定义 WEBHOOK 通知
{ "notification": { "destination": { "custom_webhook": { "url": "https://<your_webhook>" } }, "message_template": { "source": "the index is {{ctx.index}}" } } }1
2
3
4
5
6
7
8
9
10
11
12示例 3:SLACK 通知
{ "notification": { "destination": { "slack": { "url": "https://hooks.slack.com/services/xxx/xxxxxx" } }, "message_template": { "source": "the index is {{ctx.index}}" } } }1
2
3
4
5
6
7
8
9
10
11
12
可以
ctx在消息中使用变量来表示基于策略过去执行情况的多个策略参数。
ctx每项政策均提供以下变量选项:
| 范围 | 描述 | 类型 |
|---|---|---|
index | 索引的名称。 | string |
index_uuid | 索引的 uuid。 | string |
policy_id | 策略的名称。 | string |
# 快照(snapshot)
备份集群的索引和状态。
该snapshot操作具有以下参数:
| 范围 | 描述 | 类型 | 必需 | 默认 |
|---|---|---|---|---|
repository | 通过本机快照 API 操作注册的存储库名称。 | string | 是 | - |
snapshot | 快照的名称。接受字符串和 Mustache 变量and。如果 Mustache 变量无效,则快照名称默认为索引的名称。 | string或 Mustache 模板 | 是 | - |
{
"snapshot": {
"repository": "my_backup",
"snapshot": ""
}
}
2
3
4
5
6
# 索引优先级(index_priority)
设置特定状态下索引的优先级。只要有可能,未分配的索引分片将按其优先级顺序恢复。优先级值较高的索引将首先恢复,然后恢复优先级值较低的索引。
该index_priority操作具有以下参数:
| 范围 | 描述 | 类型 | 必需 | 默认 |
|---|---|---|---|---|
priority | 索引进入某种状态时的优先级。 | number | 是 | 1 |
"actions": [
{
"index_priority": {
"priority": 50
}
}
]
2
3
4
5
6
7
# 分配(allocation)
将索引分配给具有特定属性集的节点,如下所示。例如,设置require为warm仅将数据移动到“温”节点。
该allocation操作具有以下参数:
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
require | 将索引分配给具有指定属性的节点。 | string | 是 |
include | 将索引分配给具有任何指定属性的节点。 | string | 是 |
exclude | 否要将索引分配给具有任何指定属性的节点。 | string | 是 |
wait_for | 等待策略执行后再将索引分配给具有指定属性的节点。 | string | 是 |
"actions": [
{
"allocation": {
"require": { "temp": "warm" }
}
}
]
2
3
4
5
6
7
# 卷起(rollup)
索引卷起可通过将旧数据汇总到汇总索引中来定期减少数据粒度。
汇总作业可以是连续的,也可以是不连续的。使用 ISM 策略创建的汇总作业只能是非连续的。
路径和 HTTP 方法
PUT _plugins/_rollup/jobs/<rollup_id> GET _plugins/_rollup/jobs/<rollup_id> DELETE _plugins/_rollup/jobs/<rollup_id> POST _plugins/_rollup/jobs/<rollup_id>/_start POST _plugins/_rollup/jobs/<rollup_id>/_stop GET _plugins/_rollup/jobs/<rollup_id>/_explain1
2
3
4
5
6ISM 汇总策略示例
{ "policy": { "description": "Sample rollup" , "default_state": "rollup", "states": [ { "name": "rollup", "actions": [ { "rollup": { "ism_rollup": { "description": "Creating rollup through ISM", "target_index": "target", "page_size": 1000, "dimensions": [ { "date_histogram": { "fixed_interval": "60m", "source_field": "order_date", "target_field": "order_date", "timezone": "America/Los_Angeles" } }, { "terms": { "source_field": "customer_gender", "target_field": "customer_gender" } }, { "terms": { "source_field": "day_of_week", "target_field": "day_of_week" } } ], "metrics": [ { "source_field": "taxless_total_price", "metrics": [ { "sum": {} } ] }, { "source_field": "total_quantity", "metrics": [ { "avg": {} }, { "max": {} } ] } ] } } } ], "transitions": [] } ] } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# 转换(transitions)
转移定义了状态改变需要满足的条件。当前状态下的所有操作完成后,策略开始检查转换条件。
ISM 按照转换的定义顺序对其进行评估。例如,如果您定义转换:[A,B,C,D],ISM 会遍历此转换列表,直到找到一个计算结果为真的转换,然后停止并将下一个状态设置为该转换中定义的状态。在下一次执行时,ISM 将忽略其余转换并从新状态开始。
如果未在转换中指定任何条件并将其留空,则假定它相当于始终为真。这意味着策略在检查时将索引转换为此状态。
下表列出了可以为转换定义的参数。
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
state_name | 满足条件时要转换到的状态的名称。 | string | 是 |
conditions | 列出转变的条件。 | list | 是 |
该conditions对象具有以下参数:
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
min_index_age | 转换所需的指数的最低年龄。 | string | 否 |
min_rollover_age | 发生转移后过渡到下一状态所需的最低年龄。 | string | 否 |
min_doc_count | 转换所需的索引的最小文档数。 | number | 否 |
min_size | 转换所需的主分片存储总量(不计算副本)的最小大小。例如,如果设置min_size为 100 GiB,并且的索引有 5 个主分片和 5 个副本分片,每个分片大小为 20 GiB,则所有主分片的总大小为 100 GiB,因此的索引将转换到下一个状态。 | string | 否 |
cron | cron如果没有其他转换先发生,则触发转换的作业。 | object | 否 |
cron.cron.expression | cron触发转换的表达式。 | string | 是 |
cron.cron.timezone | 触发转换的时区。 | string | 是 |
以下示例将索引转换为cold30 天后的状态:
"transitions": [
{
"state_name": "cold",
"conditions": {
"min_index_age": "30d"
}
}
]
2
3
4
5
6
7
8
ISM 根据设置的时间间隔检查每次执行策略时的条件。
此示例使用cron条件每周六太平洋时间 5:00 转换索引:
"transitions": [
{
"state_name": "cold",
"conditions": {
"cron": {
"cron": {
"expression": "* 17 * * SAT",
"timezone": "America/Los_Angeles"
}
}
}
}
]
2
3
4
5
6
7
8
9
10
11
12
13
请注意,此条件不会在下午 5:00 准时执行;作业仍会根据设置执行job_interval。由于开始时间存在差异,以及在检查过渡条件之前完成操作所需的时间量,我们建议不要使用过于狭窄的 cron 表达式。例如,不要使用15 17 * * SAT(星期六下午 5:15)。
本例中使用的一个小时的窗口通常就足够了,但可以将其增加到 2-3 小时,以避免错过窗口并不得不等待一周才能发生转换。或者,可以使用更广泛的表达方式,例如让转换* * * * SAT,SUN在周末的任何时间发生。
# 错误通知
如果托管索引失败,此操作会发送通知。它会使用自定义消息error_notification通知单个目标或通知渠道。
在策略级别设置错误通知:
{
"policy": {
"description": "hot warm delete workflow",
"default_state": "hot",
"schema_version": 1,
"error_notification": { },
"states": [ ]
}
}
2
3
4
5
6
7
8
9
| 范围 | 描述 | 类型 | 必需 |
|---|---|---|---|
destination | 目标 URL。 | Slack, Amazon Chime, or webhook URL | 如果channel没有指定,则为是 |
channel | 通知渠道 ID | string | 如果destination没有指定,则为是 |
message_template | 消息文本。可以使用Mustache 模板向消息添加变量。 | object | 是 |
目标系统必须返回响应,否则error_notification操作将引发错误。
- CHIME 通知
{
"error_notification": {
"destination": {
"chime": {
"url": "<url>"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
2
3
4
5
6
7
8
9
10
11
12
- 示例 2:自定义 WEBHOOK 通知
{
"error_notification": {
"destination": {
"custom_webhook": {
"url": "https://<your_webhook>"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
2
3
4
5
6
7
8
9
10
11
12
- 示例 3:SLACK 通知
{
"error_notification": {
"destination": {
"slack": {
"url": "https://hooks.slack.com/services/xxx/xxxxxx"
}
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
2
3
4
5
6
7
8
9
10
11
12
- 示例 4:使用通知渠道
{
"error_notification": {
"channel": {
"id": "some-channel-config-id"
},
"message_template": {
"source": "The index {{ctx.index}} failed during policy execution."
}
}
}
2
3
4
5
6
7
8
9
10
# ISM策略托管索引
使用托管索引操作更改或更新策略。
下表列出了托管索引操作的字段。
| 范围 | 描述 | 类型 | 必需 | 只读 |
|---|---|---|---|---|
name | 托管索引策略的名称。 | string | 是 | 否 |
index | 此策略管理的托管索引的名称。 | string | 是 | 否 |
index_uuid | 索引的 uuid。 | string | 是 | 否 |
enabled | 为true时候,托管索引由调度程序调度并运行。 | boolean | 是 | 否 |
enabled_time | 上次启用托管索引的时间。如果托管索引进程已禁用,则此值为空。 | timestamp | 是 | 是 |
last_updated_time | 管理索引的上次更新时间。 | timestamp | 是 | 是 |
schedule | 托管索引作业的计划。 | object | 是 | 否 |
policy_id | 此托管索引使用的策略的名称。 | string | 是 | 否 |
policy_seq_no | 此托管索引使用的策略的序列号。 | number | 是 | 否 |
policy_primary_term | 此管理索引使用的策略的主要术语。 | number | 是 | 否 |
policy_version | 此托管索引使用的策略的版本。 | number | 是 | 是 |
policy | 运行期间使用的策略的缓存 JSON policy_version。如果策略为空,则表示这是作业的第一次执行,并且读取/保存了最新的策略文档。 | object | 否 | 否 |
change_policy | 关于要改变的政策和状态的信息。 | object | 否 | 否 |
policy_name | 要更新到的策略的名称。要更新到最新版本,请将其设置为与当前版本相同policy_name。 | string | 否 | 是 |
state | 托管索引完成更新后的状态。如果未指定状态,则假定策略结构未发生变化。 | string | 否 | 是 |
以下示例显示了托管索引策略:
{
"managed_index": {
"name": "my_index",
"index": "my_index",
"index_uuid": "sOKSOfkdsoSKeofjIS",
"enabled": true,
"enabled_time": 1553112384,
"last_updated_time": 1553112384,
"schedule": {
"interval": {
"period": 1,
"unit": "MINUTES",
"start_time": 1553112384
}
},
"policy_id": "log_rotation",
"policy_version": 1,
"policy": {...},
"change_policy": null
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 更改政策
更改任何托管索引策略,但 ISM 有一些限制以确保策略更改不会破坏索引。
如果索引停留在当前状态,无法继续,想要立即更新其策略,请确保新策略包含与旧策略相同的状态(相同的名称、相同的操作、相同的顺序)。在这种情况下,即使策略正在执行操作,ISM 也会应用新策略。
如果更新策略时未包含相同状态,则 ISM 仅在当前状态下的所有操作执行完毕后才会更新策略。或者,可以在旧策略中选择一个特定状态,在此之后新策略生效。
# IK分词-中文分词
为了在ASE中获取更好的中文分词效果,ASE服务集成了 IK 分词插件,并为该插件提供了结巴分词的词库和 IK 自带的词库。
下面是ASE使用IK分词的样例:
- 创建索引
PUT /ik-test
- 创建mapping
POST /ik-test/_mapping
{
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
2
3
4
5
6
7
8
9
10
- 创建文档
POST /ik-test/_create/1
{
"content": "美国留给伊拉克的是个烂摊子吗"
}
POST /ik-test/_create/2
{
"content": "公安部:各地校车将享最高路权"
}
POST /ik-test/_create/3
{
"content": "中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"
}
POST /ik-test/_create/4
{
"content": "中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
- 查看分词效果
POST /ik-test/_search
{
"query": {
"match": {
"content": "中国"
}
},
"highlight": {
"pre_tags": [
"<tag1>",
"<tag2>"
],
"post_tags": [
"</tag1>",
"</tag2>"
],
"fields": {
"content": {}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 常见配置修改和说明
# 端口修改
修改HTTP API 端口 (默认为 9200)
- 配置文件: ase安装目录/config/ase.yml
http.port: 92001
修改Transport 端口 (默认为 9300)
- 配置文件: ase安装目录/config/ase.yml
transport.port: 93001
# ASE配置局域网或其他IP访问
ASE默认只能通过本机127.0.0.1或者localhost访问,如果需要局域网或不限制,可以通过修改监听地址实现。
- 配置文件: ase安装目录/config/ase.yml
- 配置项:
network.host、discovery.seed_hosts和cluster.initial_cluster_manager_nodes - 如下配置所示,支持局域网内通过
172.20.140.58访问,如果不限制访问,可以修改为0.0.0.0
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
#network.host: 192.168.0.1
#
# Set a custom port for HTTP:
#
http.port: 9200
network.host: 172.20.140.58 #监听IP地址
discovery.seed_hosts: ["172.20.140.58"]
# 单节点部署(非集群模式),还要配置如下
cluster.initial_cluster_manager_nodes: ["172.20.140.58:9300"]
2
3
4
5
6
7
8
9
10
11
12
13
14
# License验证和使用
ASE支持本地授权和统一授权,其中本地授权采用把授权文件拷贝到产品安装目录进行授权,而统一授权则是通过在产品指定统一授权中心的连接信息进行连接授权。
# 本地授权
- 获取本机特征码:
直接启动ase,等待启动失败后,查看安装目录下的:
LICENSE-kbc_authorize_code.txt文件,获取授权码
LICENSE-kbc_authorize_code.txt文件内容是以SZTY开头的字符串,此字符串就是当前机器的授权码。
- 获取授权码后,请与金蝶天燕联系,将特征码发回金蝶天燕进行授权文件获取,或者登录金蝶天燕授权平台获取授权文件。
- 将获取到的授权文件修改为文件名license.xml,然后放到ASE安装目录下。
# 统一授权
- 统一授权中心必须包含ASE的有效授权信息。(请登录授权中心进行查看,若没有有效的产品授权信息,请参考授权中心手册,导入有效的产品授权信息。)
- 产品配置连接授权中心的连接方式:
- acls.properties配置文件: acls.properties配置文件放置在ALB安装目录下。
apusic_acls_enable=false # 开启变量统一授权 apusic_acls_authUrls=192.168.101.34 # 统一授权中心地址 apusic_acls_ns=public # 命名空间 apusic_acls_tenant=public # 租户名称1
2
3
4 - 系统环境变量配置
export apusic_acls_enable=true # 开启变量统一授权 export apusic_acls_authUrls=172.24.3.116:6869 # 统一授权中心地址 export apusic_acls_ns=后付费 # 命名空间 export apusic_acls_tenant=user_env中文 # 租户名称1
2
3
4 - JVM参数中统一授权
-Dapusic_acls_enable=true -Dapusic_acls_authUrls=172.24.3.100:6869 -Dapusic_acls_tenant=租户名称 -Dapusic_acls_ns=命名空间名称1
2
3
4
备注:3种配置如果都进行了配置,则优先级为JVM参数配置 > 系统环境变量配置 > acls.properties文件配置;如果同时配置了本地授权方式和统一授权方式,则使用统一授权方式,若授权验证失败,将不会执行后续的授权验证。
# SSL和设置admin用户密码
ASE支持使用安全的SSL通信和基于base-auth的用户验证。
# 启用SSL和用户验证
- 设置默认用户admin的密码,用户密码规范有下面几点(同时满足):
- 最少8个字符
- 最少一个大写字符
- 最少一个小写字符
- 最少包含一个数字
- 最少包含一个特殊字符
- 1、使用export设置环境变量方式配置admin用户密码为:Apusic@ase123
# 比如export设置的Apusic@ase123
export OPENSEARCH_INITIAL_ADMIN_PASSWORD=Apusic@ase123
2
- 2、执行初始化SSL证书和创建用户脚本:
./plugins/opensearch-security/tools/install_configuration.sh - 3、执行初始化脚本,出现
Enable cluster mode? [y/N]请根据是否集群模式进行选择
./plugins/opensearch-security/tools/install_configuration.sh
OpenSearch Security Demo Installer
** Warning: Do not use on production or public reachable systems **
Install demo certificates? [y/N] y
Initialize Security Modules? [y/N] y
Cluster mode requires maybe additional setup of:
- Virtual memory (vm.max_map_count)
Enable cluster mode? [y/N] n
Basedir: /Users/XXXXX/Test/opensearch-*
OpenSearch install type: .tar.gz on
OpenSearch config dir: /Users/XXXXX/Test/opensearch-*/config
OpenSearch config file: /Users/XXXXX/Test/opensearch-*/config/opensearch.yml
OpenSearch bin dir: /Users/XXXXX/Test/opensearch-*/bin
OpenSearch plugins dir: /Users/XXXXX/Test/opensearch-*/plugins
OpenSearch lib dir: /Users/XXXXX/Test/opensearch-*/lib
Detected OpenSearch Version: x-content-*
Detected OpenSearch Security Version: *
### Success
### Execute this script now on all your nodes and then start all nodes
### OpenSearch Security will be automatically initialized.
### If you like to change the runtime configuration
### change the files in ../config and execute:
"/Users/XXXXX/Test/opensearch-*/plugins/opensearch-security/tools/securityadmin.sh" -cd "/Users/XXXXX/Test/opensearch-*/config/opensearch-security/" -icl -key "/Users/XXXXX/Test/opensearch-*/config/kirk-key.pem" -cert "/Users/XXXXX/Test/opensearch-*/config/kirk.pem" -cacert "/Users/XXXXX/Test/opensearch-*/config/root-ca.pem" -nhnv
### or run ./securityadmin_demo.sh
### To use the Security Plugin ConfigurationGUI
### To access your secured cluster open https://<hostname>:<HTTP port> and log in with admin/<your-admin-password>.
### (Ignore the SSL certificate warning because we installed self-signed demo certificates)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- 4、重启ASE
- 5、使用curl测试(把下面IP换成127.0.0.1或节点IP)
curl -X GET https://172.18.100.218:9200 -u "admin:Apusic@ase123" --insecure
{
"name" : "alb",
"cluster_name" : "ase",
"cluster_uuid" : "tlY04ZldToyq7eQCH6391g",
"version" : {
"distribution" : "ase",
"number" : "2.13.0",
"build_type" : "tar",
"build_hash" : "ac4ba974ce1402554b1b8aa1a5c0402d1d1b992e",
"build_date" : "2024-07-25T02:23:42.986326873Z",
"build_snapshot" : false,
"lucene_version" : "9.9.2",
"minimum_wire_compatibility_version" : "7.10.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "The ASE Project: https://www.apusic.com/"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 禁用HTTPS
在config/ase.yml文件中的,把153行的plugins.security.ssl.http.enabled修改为false
plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem
plugins.security.ssl.transport.enforce_hostname_verification: false
plugins.security.ssl.http.enabled: false # 这个修改false
plugins.security.ssl.http.pemcert_filepath: esnode.pem
2
3
4
修改完成后,重启ase即可。
# 重新设置用户和密码
在已经由用户名和密码的前提,重新设置用户和密码,需要删除config/ase.yml配置文件中的如以下配置:
######## Start OpenSearch Security Demo Configuration ########
# WARNING: revise all the lines below before you go into production
plugins.security.ssl.transport.pemcert_filepath: esnode.pem
plugins.security.ssl.transport.pemkey_filepath: esnode-key.pem
plugins.security.ssl.transport.pemtrustedcas_filepath: root-ca.pem
plugins.security.ssl.transport.enforce_hostname_verification: false
plugins.security.ssl.http.enabled: true
plugins.security.ssl.http.pemcert_filepath: esnode.pem
plugins.security.ssl.http.pemkey_filepath: esnode-key.pem
plugins.security.ssl.http.pemtrustedcas_filepath: root-ca.pem
plugins.security.allow_unsafe_democertificates: true
plugins.security.allow_default_init_securityindex: true
plugins.security.authcz.admin_dn: ['CN=kirk,OU=client,O=client,L=test,C=de']
plugins.security.disabled: false
plugins.security.audit.type: internal_opensearch
plugins.security.enable_snapshot_restore_privilege: true
plugins.security.check_snapshot_restore_write_privileges: true
plugins.security.restapi.roles_enabled: [all_access, security_rest_api_access]
plugins.security.system_indices.enabled: true
plugins.security.system_indices.indices: [.plugins-ml-agent, .plugins-ml-config, .plugins-ml-connector,
.plugins-ml-controller, .plugins-ml-model-group, .plugins-ml-model, .plugins-ml-task,
.plugins-ml-conversation-meta, .plugins-ml-conversation-interactions, .plugins-ml-memory-meta,
.plugins-ml-memory-message, .plugins-ml-stop-words, .opendistro-alerting-config,
.opendistro-alerting-alert*, .opendistro-anomaly-results*, .opendistro-anomaly-detector*,
.opendistro-anomaly-checkpoints, .opendistro-anomaly-detection-state, .opendistro-reports-*,
.opensearch-notifications-*, .opensearch-notebooks, .opensearch-observability, .ql-datasources,
.opendistro-asynchronous-search-response*, .replication-metadata-store, .opensearch-knn-models,
.geospatial-ip2geo-data*, .plugins-flow-framework-config, .plugins-flow-framework-templates,
.plugins-flow-framework-state]
node.max_local_storage_nodes: 3
######## End OpenSearch Security Demo Configuration ########
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
即删除:######## Start OpenSearch Security Demo Configuration ########和######## End OpenSearch Security Demo Configuration ########包裹的配置内容。
删除完后,重新按照上面教程初始化即可。
# Prometheus监控接口
ASE默认开启prometheus监控,在启动ASE成功后,可以通过浏览器输入http://节点IP:端口/_prometheus/metrics
注 如果访问失败,请确保下面配置:
- ASE开启了局域网访问
- 使用https协议访问
# SSL下Prometheus配置
如果ASE启用https和用户验证,需要配置以下的内容,配置样例如下:
job_name: 'spring-actuator'
scheme: https
basic_auth:
username: 'ase用户名'
password: 'ase用户密码'
tls_config:
insecure_skip_verify: true
metrics_path: '/_promethues/metrics'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9200']
2
3
4
5
6
7
8
9
10
11
- basic_auth中的username和password需要替换成ASE的用户名和密码
# metrics请求样例(使用curl)
- 未开启HTTPS和用户验证curl:
curl -X GET http://127.0.0.1:9200/_prometheus/metrics - 开启HTTPS和用户验证:
curl -X GET https://127.0.0.1:9200/_prometheus/metrics -u 'admin:Apusic@ase123' --insecure
# HELP opensearch_indices_percolate_count Count of percolates
# TYPE opensearch_indices_percolate_count gauge
# HELP opensearch_index_translog_uncommitted_operations_number Current number of uncommitted translog operations
# TYPE opensearch_index_translog_uncommitted_operations_number gauge
# HELP opensearch_indices_merges_total_size_bytes Count of bytes of merged documents
# TYPE opensearch_indices_merges_total_size_bytes gauge
opensearch_indices_merges_total_size_bytes{cluster="ase",node="user-PC",nodeid="f3I0E0GBQ32cC0bJXNuZ-A",} 0.0
# HELP opensearch_ingest_pipeline_processor_total_failed_count Ingestion total failed
# TYPE opensearch_ingest_pipeline_processor_total_failed_count gauge
# HELP opensearch_jvm_mem_nonheap_committed_bytes Committed bytes apart from heap
# TYPE opensearch_jvm_mem_nonheap_committed_bytes gauge
opensearch_jvm_mem_nonheap_committed_bytes{cluster="ase",node="user-PC",nodeid="f3I0E0GBQ32cC0bJXNuZ-A",} 1.01777408E8
# HELP opensearch_fs_io_total_read_bytes Total IO read bytes
# TYPE opensearch_fs_io_total_read_bytes gauge
opensearch_fs_io_total_read_bytes{cluster="ase",node="user-PC",nodeid="f3I0E0GBQ32cC0bJXNuZ-A",} 655360.0
# HELP opensearch_cluster_inflight_fetch_number Number of in flight fetches
# TYPE opensearch_cluster_inflight_fetch_number gauge
opensearch_cluster_inflight_fetch_number{cluster="ase",} 0.0
# HELP opensearch_ingest_pipeline_total_current Ingestion total current
# TYPE opensearch_ingest_pipeline_total_current gauge
# HELP opensearch_transport_tx_packets_count Sent packets
# TYPE opensearch_transport_tx_packets_count gauge
opensearch_transport_tx_packets_count{cluster="ase",node="user-PC",nodeid="f3I0E0GBQ32cC0bJXNuZ-A",} 0.0
# HELP opensearch_ingest_pipeline_processor_total_count Ingestion total number
# TYPE opensearch_ingest_pipeline_processor_total_count gauge
# HELP opensearch_index_get_current_number Current rate of get commands
# TYPE opensearch_index_get_current_number gauge
# HELP opensearch_index_segments_memory_bytes Memory used by segments
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# ASE兼容es客户端版本说明
ASE推荐使用es7.4.x ~ es7.17.x之间版本的客户端,具体兼容性如下:
es7.1.1版本(不推荐使用)
- 基本索引、文档增删改查(使用存在错误)
- 术语查询,全文查询(除却matchboolprefix查询),复合查询,地理查询(除却geoshape查询),跨度查询
- ISM策略
es7.2.1版本(不推荐使用)
- 基本索引、文档增删改查(使用存在错误)
- 术语查询,全文查询,复合查询,地理查询(除却geoshape查询),跨度查询
- ISM策略
es7.3.1版本(不推荐使用)
- 基本索引、文档增删改查(使用存在错误)
- 术语查询,全文查询,复合查询,地理查询(除却geoshape查询),跨度查询
- ISM策略
es7.4.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.5.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.6.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.7.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.8.1版本-功能实现
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.9.0版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.10.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.11.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.12.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.13.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
es7.14.1版本
- 基本索引、文档增删改查
- 术语查询,全文查询,复合查询,地理查询,跨度查询
- ISM策略
# SDK 集成使用说明
ASE兼容elasticsearch客户端(具体参考:ASE兼容es客户端版本说明),可以直接使用elasticsearch的客户端或驱动进行连接,连接和配置方式可以参照elasticsearch接入说明即可。
注:JAVA的ES客户端版本参照上一章节《ASE兼容es客户端版本说明》
# Java连接和使用ASE样例
//ASE测试连接代码
public static void main(String[] args) throws Exception {
//创建ASE客户端
RestHighLevelClient aseClient = new RestHighLevelClient(
//连接地址,接口,连接方式
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//关闭ASE客户端
aseClient.close();
}
//创建索引
public static void main(String[] args) throws Exception {
RestHighLevelClient aseClient = new RestHighLevelClient(
//连接地址,接口,连接方式
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
CreateIndexRequest user = new CreateIndexRequest("user");
CreateIndexResponse response = aseClient.indices().create(user, RequestOptions.DEFAULT);
//响应状态
boolean acknowledged = response.isAcknowledged();
System.out.println("索引操作,"+ acknowledged);
//关闭ase客户端
aseClient.close();
}
// 查询索引
public static void main(String[] args) throws Exception {
RestHighLevelClient aseClient = new RestHighLevelClient(
//连接地址,接口,连接方式
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
GetIndexRequest user = new GetIndexRequest("user");
//获取目录数据
GetIndexResponse getIndexResponse = aseClient.indices().get(user, RequestOptions.DEFAULT);
System.out.println(getIndexResponse.getMappings());
System.out.println(getIndexResponse.getSettings());
System.out.println(getIndexResponse.getAliases());
//关闭ase客户端
aseClient.close();
}
// 插入一条数据
public static void main(String[] args) throws Exception {
RestHighLevelClient aseClient = new RestHighLevelClient(
//连接地址,接口,连接方式
RestClient.builder(new HttpHost("localhost",9200,"http"))
);
//操作插入的index
IndexRequest request = new IndexRequest("user");
//设置id
request.id("1001");
User user1 = new User();
user1.setName("张三");
user1.setAge(20);
user1.setAddress("中国");
//将插入对象JSON化
ObjectMapper objectMapper = new ObjectMapper();
String userJson = objectMapper.writeValueAsString(user1);
//指定插入数据的类型
request.source(userJson, XContentType.JSON);
//插入数据
IndexResponse index = aseClient.index(request, RequestOptions.DEFAULT);
System.out.println(index.getResult());
//关闭Es客户端
aseClient.close();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71